Stock Market Analysis
Overview
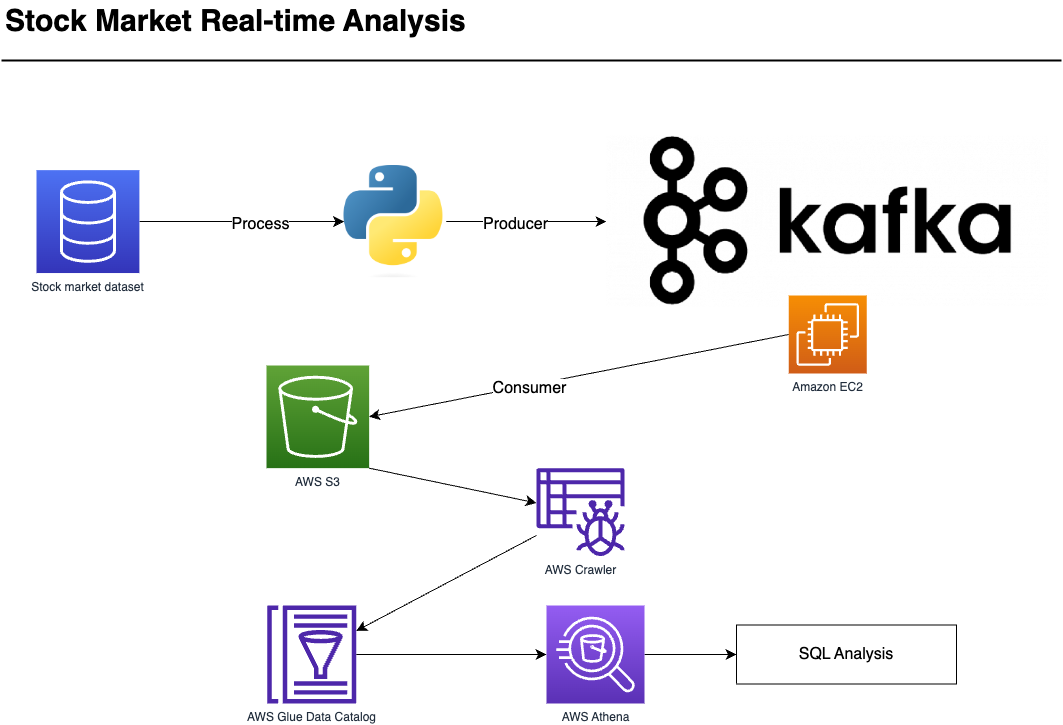
In this project, I explored Apache Kafka and its real-time data streaming capabilities. My goal was to gain hands-on experience with Kafka’s core concepts, including producers, consumers, topics, and streaming, while applying these concepts to a practical scenario involving real-time stock market data analytics.
Project Highlights
Setting up a Kafka Cluster
I began by setting up a Kafka cluster on an Amazon EC2 instance. This involved configuring Kafka brokers and ZooKeeper, ensuring seamless communication via a public IP address. This step laid the foundation for the entire data streaming process.
Generating Real-time Stock Data
To simulate real-world data, I used a stock market dataset and wrote a Python Kafka producer script. This producer continuously sent randomly selected stock data to a Kafka topic.
Real-time Data Consumption
On the other side of the spectrum, I developed a Kafka consumer script responsible for consuming data from the kafka topic. This data consumer was designed to run indefinitely, continuously receiving and processing the incoming stock market data.
Data Storage in AWS S3
The data I received from Kafka wasn’t just for real-time analysis; it was also valuable for future reference. I integrated AWS S3 into the pipeline, enabling the stock data to be written to an S3 bucket. Each piece of data was saved as a JSON file in the cloud storage.
AWS Glue and Athena Integration
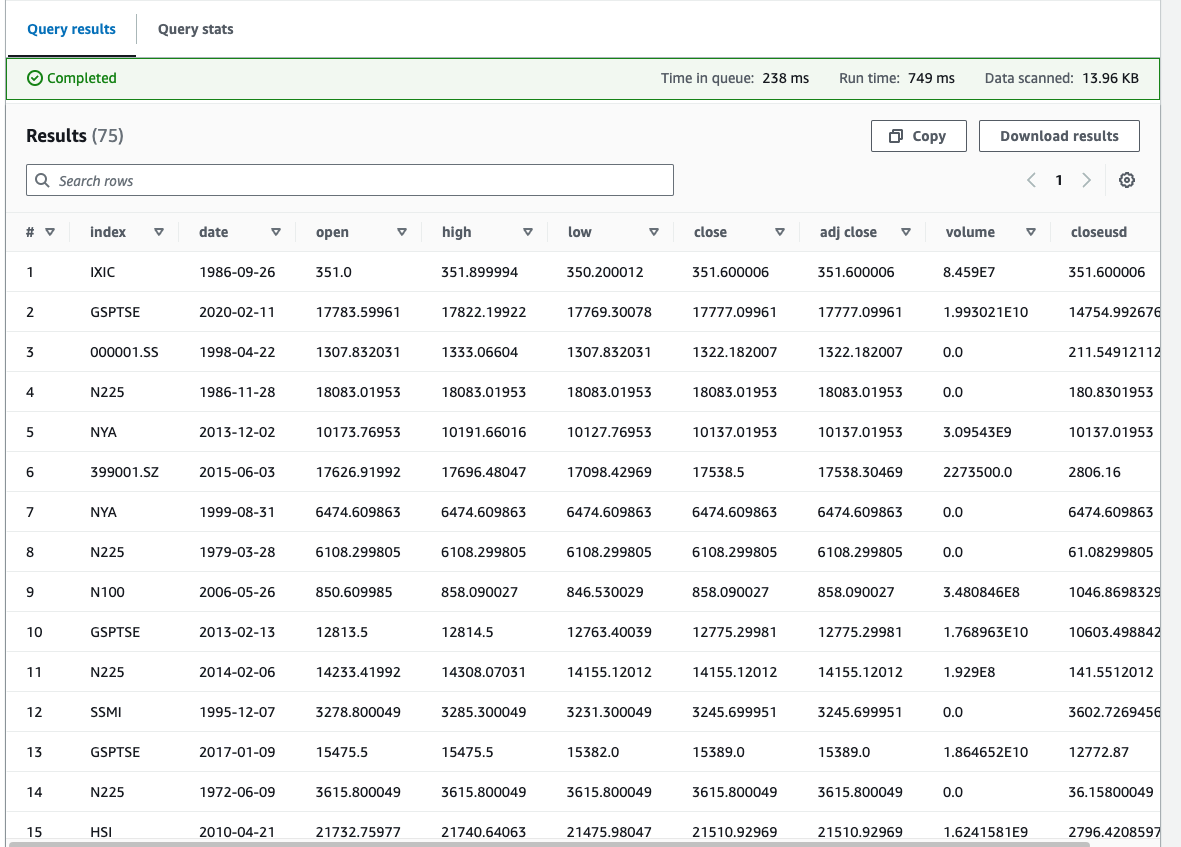
To unlock the true potential of the stored data, I used AWS Glue to create a data catalog and automatically crawled the JSON files in the S3 bucket. This facilitated data discovery and preparation. I leveraged AWS Athena, a serverless query service, to perform SQL-based analytics on the stock market data without the need for complex infrastructure setup.
Project Outcomes
This project allowed me to gain a deep understanding of Kafka’s core concepts and real-time data streaming capabilities. By integrating AWS S3, Glue, and Athena into the pipeline, I gainied proficiency in cloud-native data storage, cataloging, and analytics. The use of real-time stock market data made this project feel tangible and relevant to real-world scenarios.
Implementation
Results
Tech Stack
Python, Kafka, AWS EC2, AWS Glue, AWS Athena, SQL